El propósito de esta sesión es desarrollar gran parte de los estadísticos de la estadística de la prueba, presentar los estadísticos de las distribuciones muestrales y terminar el desarrollo con todo aquello que podemos hablar de la Regresión lineal múltiple.
Para ello el código deberá ser colocado en un archivo de script, como se le llama o simplemente módulo. El nombre de este archivo será EstDescript.py
>Puesto que el uso de las funciones nos permite independizar cálculos, haremos uso de las siguientes funciones:
Los datos serán leídos desde un archivo de texto; en este caso estamos usando el vtames.txt. Se puede leer otros archivos.
Luego de leerlos, se le quita el código de fin de línea y se le convierte en lista (Lista) via una conversión a punto flotante. Esta lista queda finalmente con el nombre x, que es lo que se envía a las funciones.
Del mismo modo, puesto que, para el cálculo de algunos estadísticos muestrales se requiere de la media y varianza poblacionales, se lee de teclado y se le envia a la función correspondiente en el momento que se la invoca.
He aquí la lista de las funciones.
- tabFrec(Lista): Ya lo hemos usado en otra sesión. Esta función, además de entregar la tabla de la distribución de frecuencias, muestra dos tipos de tráficos.
- eDescrip(Lista): Que nos permitirá obtener todos los cálculos estadíticos de la muestra.
- xmoda(Lista): Que devuelve la moda. Este estadístico es especial, ya que la muestra puede tener más de una moda.
- distN(Lista,mu,v): Esta función calcula el estadístico de la media muestral para varianza conocida, por eso se le envia la varianza en v.
- distT(Lista,mu): En este caso se obtiene el estadístico muestral con varianza desconocida.
- distCh(Lista,v): Aquí se obtiene el estadístico calculado de la Chi cuadrado,que requiere de la varianza.
- regLineal(): Esta función permite calcular todo lo relativo al capítulo de la estimación lineal múltiple. No tiene parámetros. Los datos los lee desde un archivo de texto.
Nota respecto a la gfrabación de los datos en archivo de texto:
Cuando se graben los datos, se debe tomar en cuenta si la varaiable de separación va a ser una coma (,), un punto y coma(;) o un tabulador(\t).
De preferencia se debe grabar con codificación ANSI y extensión txt. En todo caso se debe leer los datos en la consola del Python para comprobar si no presenta errores.
En muchos casos cuando se graba desde el editor o desde el Excel, como DOS tx o cvs, el primer dato no es un válido y hay un último vacío ('').
Si el primer dato no es válido, se debe reemplazar por su verdadero valor. Por ejemplo: datos[0] = '>#?230.18,1200', entonces se debe hacer: datos[0] = 230.18,1200
Del mismo modo, si el último es - ' '-, es porque se grabó la última línea en blanco. Para eliminarlo, se debe usar: datos.pop(-1). Esto remueve dicho valor vacío.
Si tiene problemas con la carga de datos desde un archivo de texto y su conversión a listas numéricas, podría usar las siguientes líneas:
>>>fn = open("d:\\pypage\\ahorro.txt")
>>>datos = fn.read().split("\n") # Leemos todo el archivo y le quitamos el fin de línea
Y ahora, el siguiente procedimiento extrae las variables en formato de lista y punto flotante
>>>ahorro = []
>>>ingreso = []
>>> for i in range(len(datos)):
a, i = datos[i].split(",")
ahorro.append(float(a))
ingreso.append(float(i))
Continuemos con el tema
En cada una de dichas funciones hemos hecho uso de las funciones existentes en la librería de numpy, excepto en el caso de la moda y del coeficiente de asimetría que los hemos codificado.
La parte principal del programa, se encarga de leer los datos desde un archivo, los habilita para disponer de una lista con valores numéricos y se leen la media y varianza poblacionales.
Aqui mostramos el segmento del programa principal:
#
# Programa principal
#
fn = open("d:\\pypage\\vtames.txt")
datos = fn.read()
fn.close()
datos = datos.split("\n")
x = []
for i in range(len(datos)):
x.append(float(datos[i]))
tabFrec(x)
eDescrip(x)
mu = float(input("Ingrese la media pobacional: "))
distT(x,mu)
varPob = float(input("Ingrese la varianza pobacional: "))
distN(x,mu,varPob)
distCh(x,varPob)
regLineal()
La función regLineal no tiene parámetros puesto que, al requerirse de dos o más variables, la Lista es diferente a las demás. La lectura de los datos se hace dentro de la misma función.
El modelo se ha corrido usando el archivo agri.txt> de cuatro variables que están separados por un tabulador.
Si no desea modificar el archivo y desea correr con el mismo nombre, a sus datos debe grabarlo con el nombre agri.txt y tomar nota del separador que usa.
Al ejecutar el módulo, le pedirá el separador que se usa en el archivo. Digie una coma, un punto y coma o la palabra tab si el separador es "," , ";" , "\t".
Si sus datos lo conforman una sola variable, no tendría sentido que use regLineal().
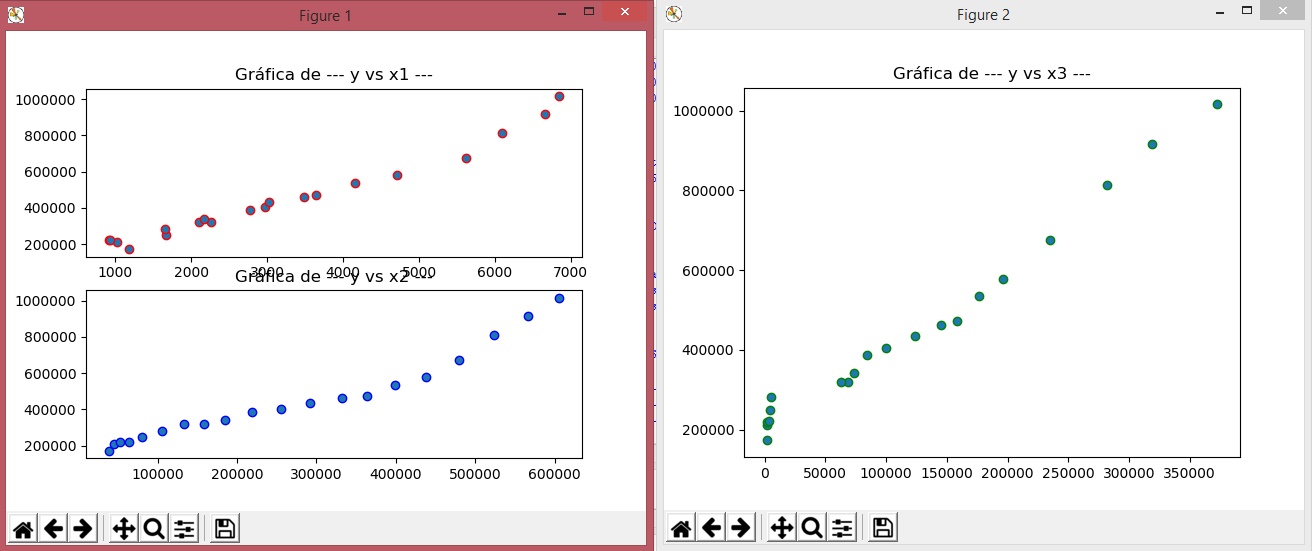
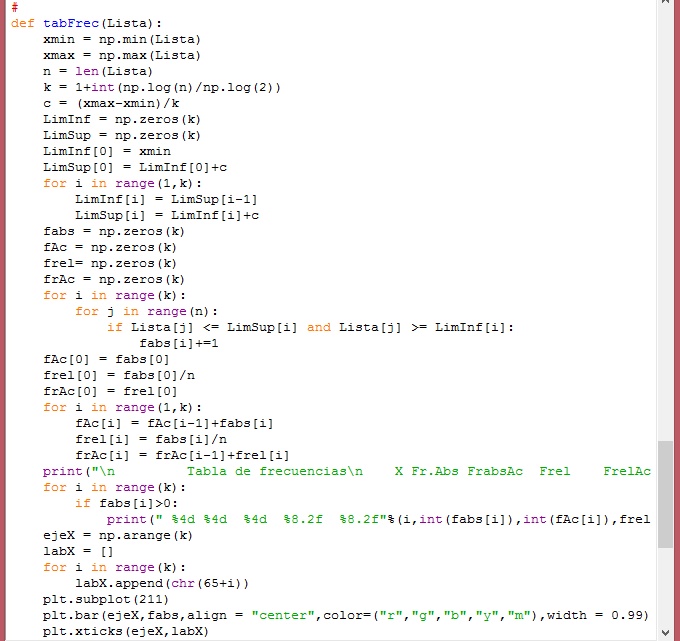
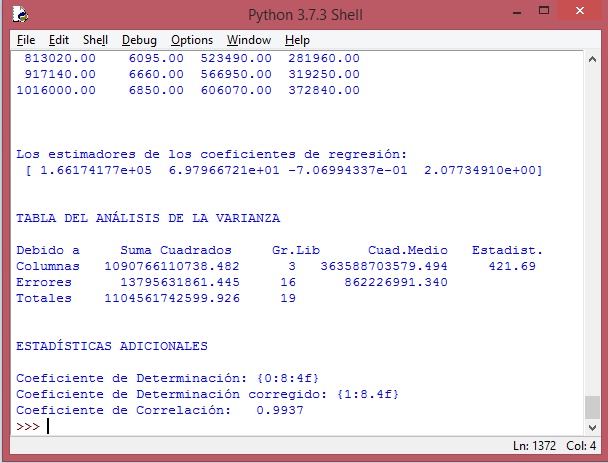
A continuación se muestra imagenes del módulo, de la corrida y de los gráficos de dispersión que cuando se trata de regresión lineal.
Emisión de la función regLineal
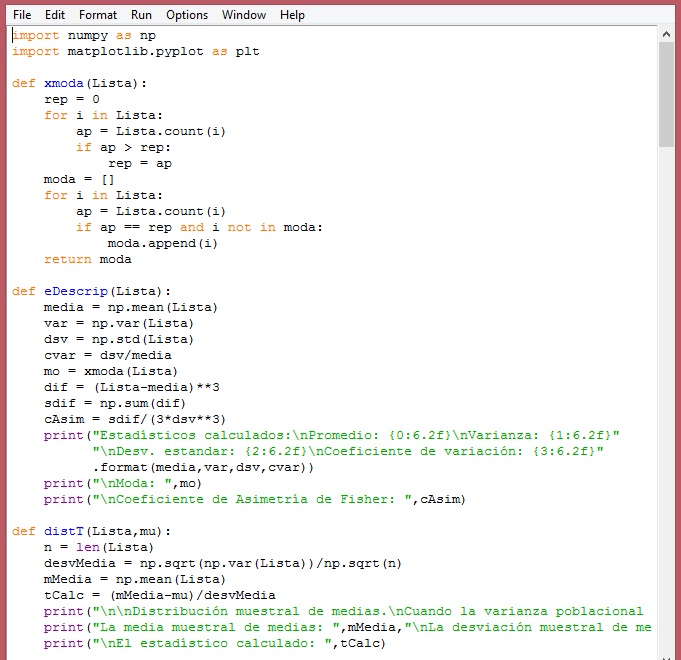
Primera y segunda parte del módulo:
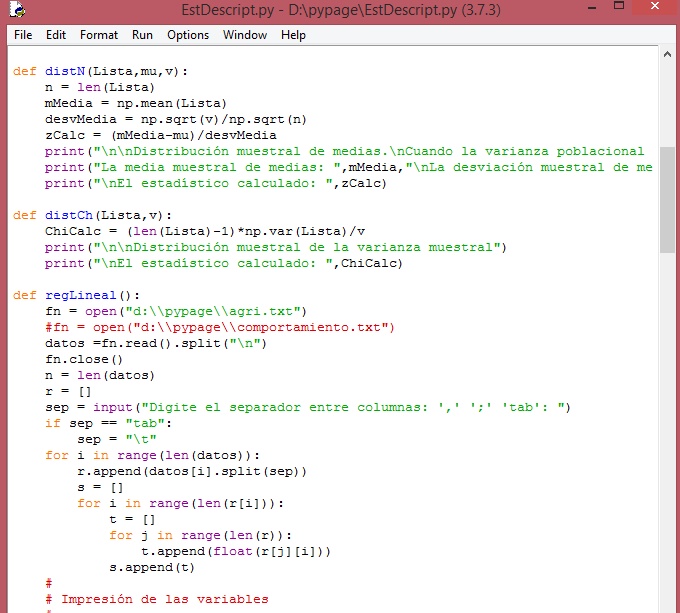
Tercera y cuarta parte del módulo:

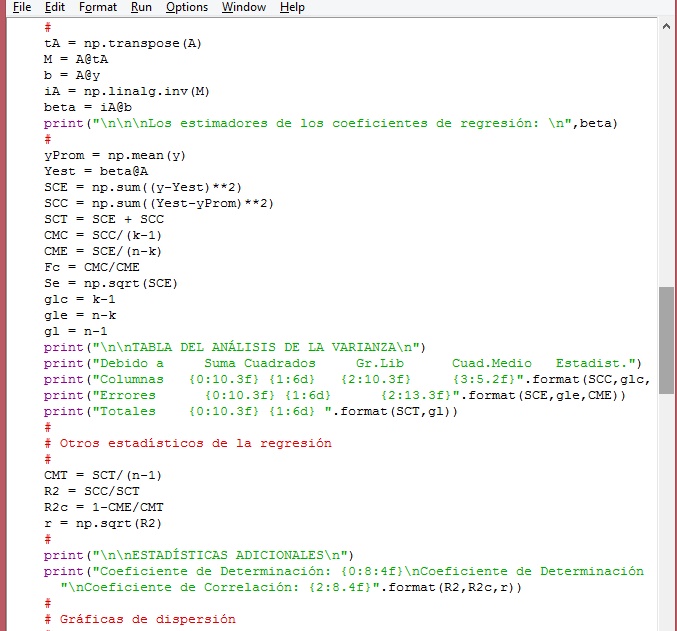
Cuarta y quinta pare del módulo
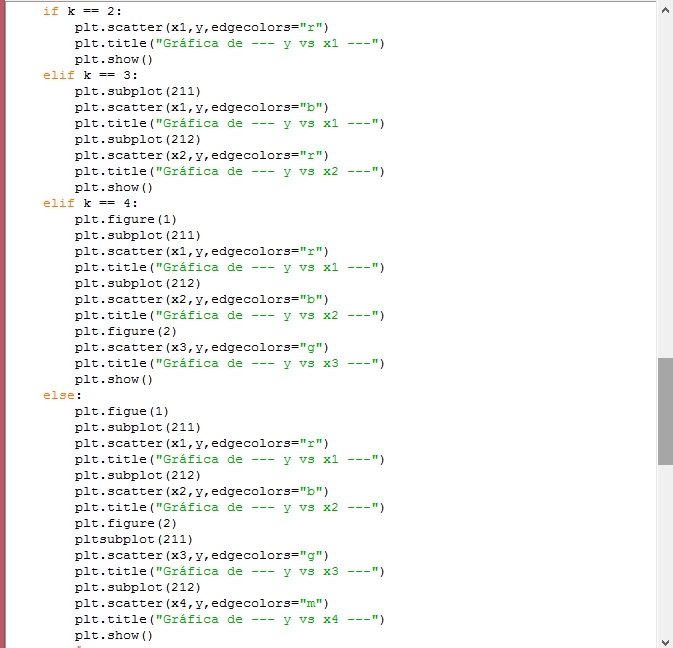
La última parte del módulo
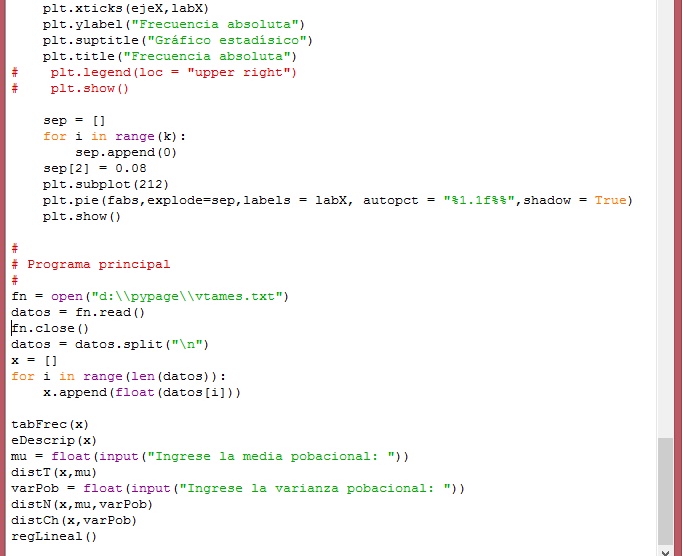
Imagen de la segunda parte de lo impreso
Finalmente las gráficas d dispersión de la variable dependiente Y y las predictoras X