En esta ocasión seguiremos trabajando con aplicaciones de un solo vector pero con algún cambio
Frecuentemente los datos que se requiere ya están grabados usando un editor o una hoja de cálculo como el Excel. Por esta razón se hace necesario la forma de leer los datos desde un archivo.
Haremos uso de archivos de texto; es decir, archivos no binarios con extensión txt o csv. Si los datos estuvieran grabados en el formato del Excel, podemos, desde allí, grabarlos como de tipo texto en formato txt o csv.
Descargue el archivo ingreso.txt y grábelo en la unidad y carpeta que desee. Si lo abre, entonces, haga clic con el botón derecho y use Guardar destino como.
Pues bien, vamos a leer el archivo ingreso.txt que se encuentra en la carpeta pypage, de la unidad D; es decir, la ruta, incluyendo el archivo es d:\pypage\ingreso.txt, como se debe indicar cuando se quiere abrir un archivo.
Primero dejamos en una variable la ruta y nombre del archivo
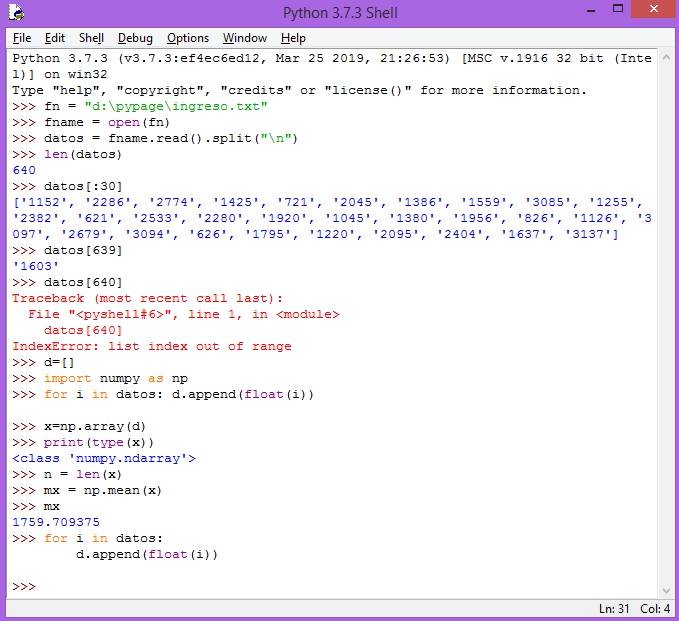
>>>nf = "d:\pypage\ingreso.txt"
Luego lo abrimos usando open(...)
>>>fname = open(nf)
Claro que pudimos haber puesto la ruta y nombre del archivo directamente como argumento de open(...), entrecomillado.
Pasmos a leer el contenido hacia una variable que, por defecto constituirá una lista.
Antes, una aclaración:
Cada línea, en un archivo cualquiera, termina su contenido con un [Intro] en el momento que se ingresa. Ese final de línea (line feed o LF) o, en el caso de las impresoras, retorno de carro y avance de línea (CR), se expresa mediante un código ASCII y constituye un caracter de conrol. En el caso de fin y cambio de línea se representa por "\n". Por esta razón, tenemos que decir que, cuando se lea una línea, ésta se transferirá a la variable hasta el fin de línea.
Por tanto, a la lectura se añadirá la función split(...) que nos permitirá remover el símbolo de fin de línea. Al final, presionamos dos veces [Intro]
>>>datos = fname.read().split("\n")
Antes de continuar, es necesario cerrar el archivo por razones de seguridad.
>>>fname.close()
Mostraremos la longitud de datos
>>>len(datos)
Veamos de qué tipo de datos es
>>>print(type(datos))
Es una lista.
Siendo una lista de gran tamaño, viualizemos los 10 primeros elementos de esta lista.
>>>datos[:10]
Observamos que no es una lista de valores numéricos. Para usarlo como vector, debemos realizar una conversión.
Ya vimos que la serie de datos no tiene cabecera, aunque podemos mostralo explícitamente:
>>>datos[0]
'1152'
Veamos si el último es un dato o un elemento vacío proveniente de una línea vacía, cuando se digitó.
Puesto que hay 640 elementos, el último tiene subíndice 639. Por tanto veamos qué nos muestra este elemento
>>>datos[639]
'1603'
Entonces el contenido de datos es correcto.
Procedemos a la conversión en vector, por lo que antes debemos importar numpy:
>>>import numpy as np
Definimos a la variable d con estructura de lista:
>>>d = []
Los declaramos previamente ya que no vamos a asignarle un valor sino vamos a añadir valores a la lista que empieza estando vacía. Esto lo aclaramos pues digimos antes que la variable define su estructura en el momento que se le asigna un valor.
La siguiente línea es una sentencia repetitiva del lenguaje. La usaremos más adelante; pero ahora lo necesitamos:
>>>for i in datos:
d.append(float(i))
Al presionar [Intro] depués de ":", el cursor se ubica debajo de la i, insertando una identación. Las identaciones, al escribir el código sun muy importante, como ya lo veremos más adelante.
Y en esa línea identada, se completa con: d.append(float(i))
Al final del cual, se presiona [Intro]. El cursos debe posicionarse debajo de d. Como ya no hay más sentencias, al presionar [Intro] por segunda vez, el cursor debe ubicarse al inicio de la línea o debajo de la "f" del for. Para mayor seguridad, debemos presionar una vez más [Intro].
Lo que hemos hecho es encuadrar el ámbito del for indicando dónde termina la secuencia de instrucciones que debe ejecutarse cada vez que i cambie de valor.
Explicación de la lógica del for:
La lista <b>datos</b> tiene 640 elementos. El primero en la posición o índice 0 y el último en la posición 639.
"for i in datos" significa que, la variable i, tomará los 640 elementos de la lista <b>datos</p>
>>> d.append(float(i))
Otros casos de for:
for each in range(10) ===> Puesto que range(9) genera una lista de 10 elementos: de 0 a 9: la variable each tomará, en cada iteración, el siguiente valor de la lista, empezando en 0 y terminando en 9, al cabo del cual, terminará de ejecutarse la sentencia o instrucción <b>for</b>.<br><br>
Continuando con el ejemplo, ahora lo tranferimos al vector x usando
>>>x = np.array(d)
El tipo de x:
>>>print(tyepe(x))
Todo esto es lo que se muestra en la siguiente imagen
ahora procedemos a crear nuestro tercer módulo que servirá mucho más que los otros pues, vamos a hacer que el módulo pida el nombre del archivo de texto y obtenga las estadísticas ya vistas anteriormente.
La única condición que tendremos que tomar en cuenta es que el archivo debe tener exensión txt o csv. Y debe contener datos de una sola variable.
En el Shell o consola de Python use la secuencia: [File] - [New file]
Guarde el archivo usando [File] - [Save as]. Ubique la unidad y carpeta donde estamos grabando. El nombre del archivo será: mymod03.py
Ahora ingrese lo siguiente:
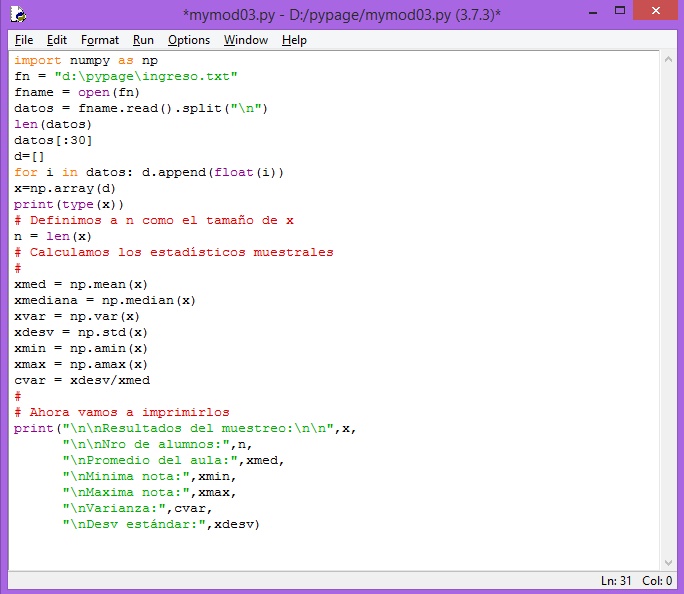
import numpy as np
fn = "d:\pypage\ingreso.txt"
Usted debe cambiar la unidad y carpeta según donde lo tenga el archivo.
fname = open(fn)
datos = fname.read().split("\n")
len(datos)
datos[:30]
d=[]
for i in datos: d.append(float(i))
x=np.array(d)
print(type(x))
Abra el módulo mymod02.py y copie las sentencias que permiten realizar el cálculo:
# Definimos a n como el tamaño de x
n = len(x)
# Calculamos los estadísticos muestrales
#
xmed = np.mean(x)
xmediana = np.median(x)
xvar = np.var(x)
xdesv = np.std(x)
xmin = np.amin(x)
xmax = np.amax(x)
cvar = xdesv/xmed
#
# Ahora vamos a imprimirlos
print("\n\nResultados del muestreo:\n\n",x,
"\n\nNro de alumnos:",n,
"\nPromedio del aula:",xmed,
"\nMinima nota:",xmin,
"\nMaxima nota:",xmax,
"\nVarianza:",cvar,
"\nDesv estándar:",xdesv)
Este debe ser el contenido del tercer módulo
Vuelva a grabar el módulo
Ahora ejecute usando [Run]-[Run module]
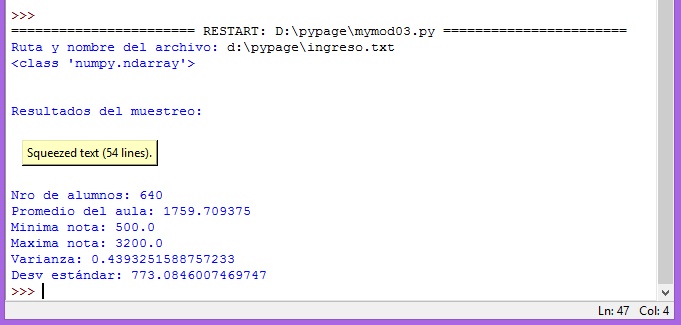
Esto es lo que se recibirá como resultado
En la misma carpeta tenemos otro archivo con el mismo contenido, pero que fue grabado con extensión CSV.
Un archivo de tipo texto, con extensión "txt" puede tener como separador de datos: ",", "\t","/", ";", etc. En cambio si su extensión es "csv", el separador es ";".
En el caso de que el archivo tenga un valor por fila, es lo mismo leer como "txt" o "csv".
En consecuencia, vamos a procesar los datos contenidos en el archivo "ingreso.csv" con el mismo módulo. Use botón izquierdo o derecho en ingreso.csv, según corresponda para descargar o grabar en su carpeta.
Vuelva a ejecutar el módulo. Cuando pida nombre de archivo, digite: d:\pypage\ingreso.csv
De inmediato obtendrá los resultados de la ejecución del módulo.