Antes de continuar con las operaciones vectoriales, vamos a completar y facilitar la lectura de archivos de datos.
Hasta ahora hemos usado la librería estándar de Python. El dato leído es una lista, que debe ser convertida a un arreglo.
Los pasos requeridos son:
>>>fn="d:\\pypage\\ingreso.txt" # Aunque podemos la ruta puede ser incluida directamente en "open(...").
>>>fname = open(fn)
>>>datos = fname.read().split("\n")
Siempre se debe cerrar de inmediato el archivo
>>>fname.close()
La impresión de algunos elementos nos sugiere que debemos convertirlo para tenerlo en un arreglo
>>>datos[:10]
Primero definimos a una variable cualquiera como un arreglo:
>>>d=[] La siguiente instrucción nos permite la conversión
>>>for i in datos: d.append(float(i)) # No se olvide de presionar [Intro] dos veces.
Explicación: Para cada valor de datos, extraído hacia i, vamos a añadirlo al arreglo d.
La impresión de algunos elementos de "d" nos muestra que ya tenemos un arreglo
>>>d[:10]
Del mismo modo, si la extensión de archivo fuera "csv", procedemos de la misma forma
>>> fname = opena("d:\\pypage\\ingreso.csv")
>>> datos = fname.read().split("\n")
Ahora para convertirlo en arreglo, usamos:
>>>otroArreglo = []
>>>for i in datos: otroArreglo.append(float(i))
Adicional a la forma de leer archivos en Python, con su propia librería, haremos uso de la librería pandas
Para ello debemos importarlo, como lo hacemos con numpy cada vez que lo necesitamos.
Importemos las dos librerías
>>>import numpy as np
>>>import pandas as pd
Ahora, pasamos a leer el archivo "ingreso.txt" usando pandas como pd.
>>>datos = pd.read_csv("d:\\pypage\\ingreso.txt")
Imprimiremos su tipo:
>>>print(type(datos))
Podemos apreciar que la estructura de datos ahora es un data.frame. Diremos, en términos simples que un data.frame es una tabla con etiquetas de fila y columna, como en una hoja de cálculo.
Ahora vamos algunos valores:
>>>datos[:10]
De la impresión de algunos elementos, observamos que el índice de fila empieza en 0 y tiene como cabecera de la columna, al primer dato. Esto lo ha cogido así pues los datos no tienen etiqueta o nombre de columna, lo que después será el nombre de la variable.
En consecuencia, vamos a afinar nuestra lectura:
>>>datos = pd.read_csv("d:\\pypage\\ingreso.txt",header=None)
Ahora sí está correcto.
Pero, si quisiéramos que la serie tuviera su propio nombre, puesto es lo que debemos hacer:
>>>datos = pd.read_csv("d:\\pypage\\ingreso.txt", names=["Ingreso"])
>>>datos[:10]
Esto está mucho mejor.
Y no se requiere conversión pues, como se puede ver:
>>>np.sum(datos)
>>>np.mean(datos)
Ya podemos obtener las estadísticas descriptivas.
Pasemos a utilizar la lectura de archivos que soporta pandas.
Vamos a leer un archivo de extensión csv:
>>>datos1=pd.read_csv("d:\\pypage\\ingreso.csv", header=None)
Archivo del Excel, de una sola columna, de extensión xlsx:
>>>datos2=pd.read_excel("d:\\pypage\\ingreso.xlsx", names=["Ingreso"])
Archivo de texto con dos columnas de datos:
>>>datos3=pd.read_csv("d:\\pypage\\ahorro.txt",names=("Ahorro","Ingreso"))
Archivo plano de extensión txt, de dos columnas:
>>>datos4=pd.read_csv("d:\\pypage\\agri.txt",header=None)
>>>datos4
Pésimo !!! ¿no?. Por lo impreso nos damos cuenta que el separador (pues se trata de dos datos por fila) es el tabulador; en consecuencia, añadimos un nuevo argumento a la función de lectura<br>
>>datos4=pd.read_csv("d:\\pypage\\agri.txt",sep="\t",header=None)
>>>datos4
Podemos mejorarlo:
>>>datos4=pd.read_csv("d:\\pypage\\agri.txt",sep="\t",names=("ProdAg","VolFit","PqAut","FinPp"))
>>>datos4
Por tanto, si no deseamos ingresar los datos directamente en la consola del Python, lo grabamos en un editor de texto o con Excel, sea de extensión txt o csv . Como hemos visto, podemos también grabarlo en formato del Excel, con extensión xlsx.
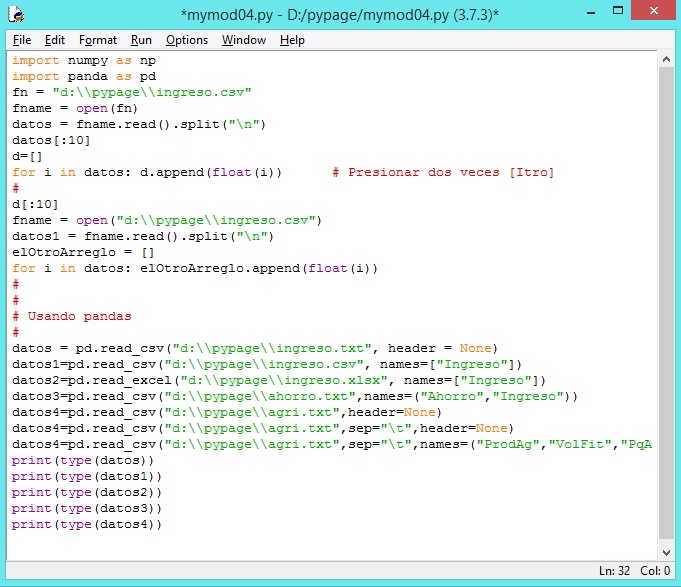
De todo lo dicho, podemos rescatar los comandos para la lectura de un archivo y crear nuestro cuarto módulo.
Esto es lo que se muestra en la siguiente imagen.