Ploteo de variables o serie de datos
Antes de empezar con gráficos especiales, hagamos algunos ejemplos de ploteo de variables o serie de datos almacenados en variable.
Haremos uso de la función seno y coseno para ver el ploteo con sus diferenes atributos.
Definamos un conjunto de valores para x
>x=seq(-3.1416,3.1416,0.05)
También podemos usar
>x=seq(-pi,pi,0.05)
Grafiquemos la función seno usando plot en su formato básico
>y=sin()
>plot(y)
Se puede hacer todo a la vez
>plot(sin(x))
Ampliemos el rango
>x=seq(-2*pi,2*pi,0.05)
>plot(sin(x))
Otro gráfico
>plot(sin(x),cos(x))
Otras variantes de plot()
>x=seq(0,2*pi,0.02)
>plot(x,cos(x),type="l",col="blue",lwd=3)
>plot(x,cos(x),type="l",col="blue",lwd=1)
Otra
>x=seq(0,2*pi,length=100)
>plot(x,cos(x),type="l",col="blue",lwd=2)
Vamos a añadir la gráfica de la función seno
>lines(x,sin(x),lwd=2)
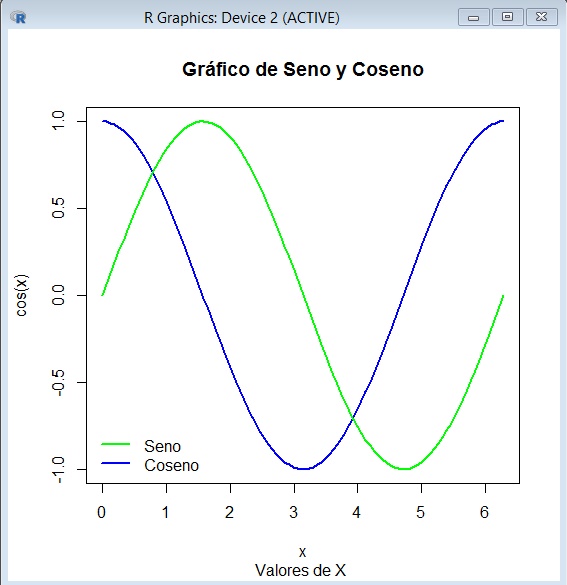
Volvemos a graficar usando colores, etiqueta y leyenda
> plot(x,cos(x),main="Gráfico de Seno y Coseno",type="l",col="blue",lwd=2)
> lines(x,sin(x),col="GREEN",lwd=2)
> legend("bottomleft",col=c("Green","Blue"),legend=c("Seno","Coseno"),lwd=2,bty="n")
>
La siguiente imagen muestra el resultado del ploteo
Otro ejemplo:
>x = seq(0,2*pi,length=100)
>y = seq(0,3*pi,length=100)
>z=sin(x)+cos(y)
> plot(z,main="Gráfico z = Seno(x)+Coseno(y)",type="l",col="blue",lwd=2)
> legend("bottomleft",col=c("Blue"),legend=c("Seno+Coseno"),lwd=2,bty="n")
Esta es la gráfica
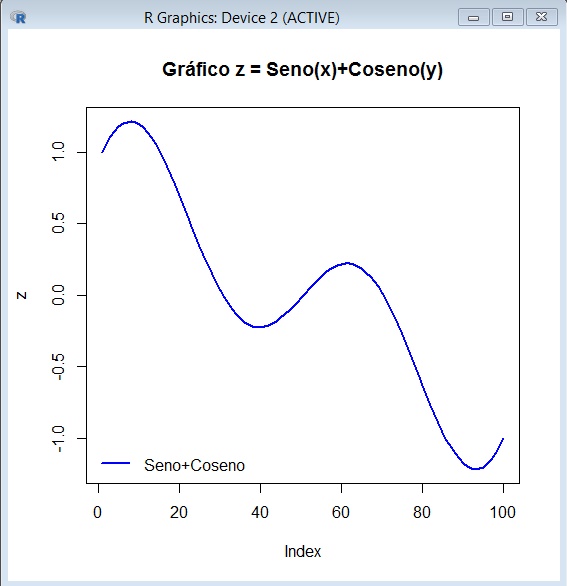
Gráfico de barras
Sintaxis: Una sintaxis algo simplificada es la siguiente:
Barplot(altura, width = 2, space = NULL, names.arg = NULL, legend.text = NULL, besides = FALSE, horiz = FALSE, col=NULL, border=pCar(‘fg’), main=NULL, sub=NULL, xlab=NULL, ylab=NULL, arg.legend = NULL)
Donde
altura : Es un vector o matriz que describe las barras a ser ploteadas.
width = 2 : Indica si va a ser visible las barras (1 no es visible)
space : Espacio entre barras. Si es NULL la separación es por omisión
names.arg : vector de nombres debajo de cada barra
legend.text : vector de leyendas colocadas en la parte superior del gráfico
besides = TRUE : las barras son puestas una al costado de la otra, FALSE, apiladas
horiz = FALSE : barras verticales, TRUE, horizontales
col = c(“red”,…) : vector de colores de cada barra
border : Color a ser usado en los bordes de las barras
main : Titulo
sub : Subtítulo
xlab = … : Etiqueta en el eje X
ylab : Etiqueta en el eje Y
arg.legend=… : Posición en la que debe insertarse la leyenda, si se ha usado legend.text
Ejemplo: args.legend = list(z = "topleft"…. Otra con “bottomright”, “topright”
Ejemplo directo:
> barplot(height=cbind(z=c(465,91)/465*100,y=c(840,200)/840*100,z=c(37,17)/37*100), beside=TRUE,horiz=FALSE,width=c(465,840,37),col=c("blue","red"),legend.text=c("A","B"),args.legend=list(z="bottomright"))
Cambie bside a FALSE
Cambie horiz a TRUE
Cambie arg.legend
Inserte después de beside, space=c(1,3,2)
Observación
Para limpiar la pantalla podemos usar [ctrl] + L
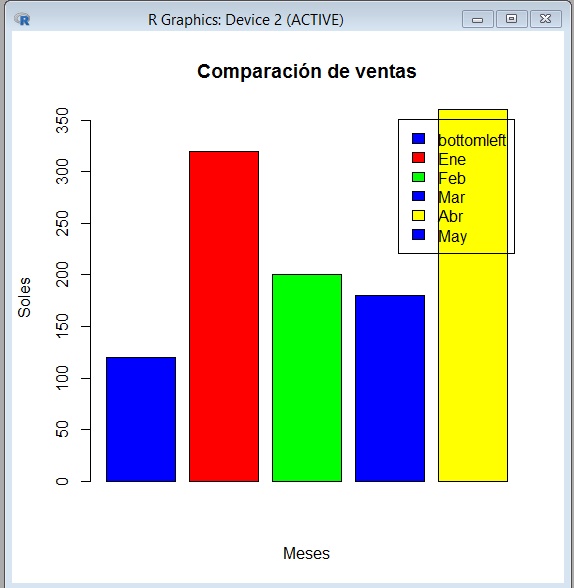
Ejemplo 1
Supongamos que se desea comparar gráficamente las ventas mensuales de Enero a Mayo.
>g=c(120,320,200,180,360)
Definimos el vector de colores y el de la leyenda directamente como argumentos de barplot(...)
> barplot(g,col=c("blue","red","green","blue","yellow"),legend= c("bottomleft","Ene","Feb", "Mar","Abr","May"),main="Comparación de ventas",xlab=”Meses”,ylab=”Soles”)
La gráfica se muestra acontinuación
Importar o leer de datos desde Excel
Hagamos un repaso de cómo leer serie de datos desde una aplicación como el Excel o SPSS.
Si antes ya se ha instalado el paquete, es suficiente cargarlo a memoria.
Si no se ha instalado se debe hacer lo siguiente:
[Paquetes] - [Instalar paquetes(s)…]. Seleccionar país, elegiremos [Brasil(PR)(https)] - De la siguiente lista seleccionamos XLSX -[Ok]
Ahora necesitamos cargarlo a memoria; para ello usamos [Paquetes] - [Cargar paquete]. De la lista seleccionar [XLSX] - [Ok]
La función que permite leer el archivo es
>d = read.xlsx(“ruta\\fn.xlsx”,h)
En nuestro caso, leeremos el archivo pagos.xlsx que está en la carpeta datos y dejamos en la variable "d"
> d=read.xlsx(“c:\\datosr\\pagos.xlsx”,1)
Importar o leer de datos desde SPSS
Se debe instalar el paquete “foreign” usando
En el caso del SPSS, se debe incluir tres argumentos para que las variables del SPSS se conviertan en factores en el R. Esta es el comando.
d=read.spss("c:\\datosr\\turivia.sav",use.value.labels=TRUE,max.value.labels=TRUE,to.data.frame=TRUE)
Podemos visualizar los datos usando >
Del mismo modo podemos usar >summary(d)
Como se puede ver, no es tan útil pues obtiene estadísticas categóricas. Podemos usar summary(d$VIAJES)
Ejemplo 2
Veamos uno simple en el cual definimos todo
Supongamos que se ha hecho una encuesta a 20 personas sobre el grado de instrucción que tienen los congresistas.
Las respuestas deben ser: 1= Sin estudios, 2=Secundaria, 3=Universidad,4=Bachiller, 5=Licenciado,6=Postgrado.
Las respuestas las recibimos en el vector g
>g=c(3,2,3,2,5,4,2,6,3,5,3,1,6,3,4,2,4,1,3,4,3,2,3,5,3,4,6,4,3,6)
Categorizamos a estos datos por niveles mediante la función factor
>f=factor(g)
Redefinimos los niveles por sus nombres literales
> levels(f)=c("Sin estudios","Secundaria","Universidad","Bachiller","Licenciado","Postgrado")
Veamos cómo está la tabla
>table(f)
Lo dejamos en el objeto t
>t=table(f)
Ahora graficamos
>barplot(t)
Vamos a añadirle un título:
>barplot(t,main=”Gráfica del grado de instrucción”)
Añadimos una descripción del eje X
>barplot(t,main=”Gráfica del grado de instrucción”,xlab=”Instrucción”)
Ahora una descripción del eje Y
> barplot(t,main="Grafica del grado de instrucción",xlab="Instrucción",ylab="nro de congresistas")
Los rellenamos de color a cada barra definiendo un vector de colores
> color=c("red","orange","magenta","yellow","blue","green")
Graficamos
> barplot(t,main="Grafica del grado de instrucción",xlab="Instrucción",ylab="nro de congresistas",col=color)
Ahora cojamos los datos originales en g y construyamos una table de frecuencias
>table(g)
Construyamos una gráfica de pie (que la veremos a continuación) para g que es numérica (f no lo es).
>pie(table(g))
Ahora trazamos el histograma de la variable original
>hist(g,main="Grafica del grado de instrucción",xlab="Instrucción",ylab="nro de congresistas",col=color)
Le añadimos la etiqueta:
>hist(g,main="Grafica del grado de instrucción",xlab="Instrucción",ylab="nro de congresistas",col=color,labels=TRUE)
Ejemplo 3
Usemos el vector de datos x, arriba definido
Para esta gráfica debemos disponer de niveles categóricos de cada barra. Para ello definiremos a x en factores y lo dejaremos en xf.
>xf = factor(x)
Podemos ver el contenido de xf
Veamos su estructura tabular
>table(xf)
Es similar a >table(x) en la que se aprecia la tabla de frecuencias absolutas
Ahora lo convertimos en tabla de frecuencia porcentual.
> t=prop.table(table(df))
Lo ploteamos
>barplot(t)
Rellenemos de color las barras:
> barplot(t,col=c(4,3,2,1,5))
Otro ejemplo definido en el momento:
Ejemplo 4
Supongamos que se ha hecho una encuesta de satisfacción sobre la atención a los pacientes en una dependencia hospitalaria.
Generemos los datos
>d=c(1,1,1,1,1,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3,3,3,3,4,4,4,4,4,5,5,5,5,5)
Podemos comprobar que hay 33 datos. Aumentemos a 50.
>d=c(d,1,1,1,2,2,2,2,2,3,3,3,3,4,4,5,5,5)
Hagamos que se convierta en factor y lo enumere.
>df = factor(d)
Puede comprobar los niveles que tiene esta nueva estructura al digitar >df.
Vamos a reemplazar los niveles 1, 2, 3, 4, 5 por valores categóricos:
Reemplacemos los nombres de los niveles en cada valor de la variable factor
>llevels(df) = c("Excelente","Bueno","Regular","Malo","Pésimo")
Veamos qué resultado se obtiene al evaluarlo como tabla:
>table(df)
Convertimos en una tabla de frecuencia relativa en términos porcentuales
>t=prop.table(table(df))*100
>t
Pasamos a graficar, pero lo dejamos en un objeto o variable
> bpt = barplot(t,las = 1, main="Calidad de servicio",sub="opinión de pacientes")
Lo graficamos:
>bpt
¿Qué cambio se obtiene si las = 2? Si fuera 3?
Usemos lo colores predeterminados:
>barplot(t,las = 3, main="Calidad de servicio",sub="opinión de pacientes",col=c(1,2,3,4,5))
>
Ahora definamos un vector de colores
> color =c("Red","Green","Blue","Orange","Yellow")
Incluyamos este argumento
> bpt = barplot(t,las = 3, col = color,main="Calidad de servicio",sub="opinión de pacientes")
Lo graficamos
>bpt
Vamos a añadirle los valores como etiqueta de cada barra
> text(bpt,c(1,1),round(t,2))
¿Qué ocurre si usamos c(5,5)?
Observación
En lugar de definir un vector de colores, pudimos haber usado:
Col = rainbow(5)
Porque son 5 barras.
Histograma de frecuencias
Se puede usar >hist…) o también >hist.default(…) <(p>
Sintaxis:
>ist.default(x, breaks, freq = NULL, right=TRUE, col=NULL, border=par(“fg”), main=paste(“Histogram of “, xname),
xlim = ranges(breaks), ylim = NULL,
xlab = xname, ylab = yname,
axes=TRUE, plot=TRUE, labels=FALSE, nclass=NULL, …)
donde
x : Es el vector de datos
breaks: Si es un valor, se indica el número aproximado de clases, si es un vector, se indica los límites entre las clases.
freq: Argumento lógico. SI es TRUE, se usa las frecuencias absolutas. Se es FALSE, las relativas
right: Los intervalos son cerrados por la derecha si es FALSE y por la derecha si es TRUE
col: Vector que define el color de las barras. NULL produce barras sin fondo
plot: Si es TRUE se produce el histograma. Si es FALSE se obtiene una lista de conteos.
nclass: Indica amplitud del intervalo. Equivalente con breaks.
labels: Si es TRUE se inserta una etiqueta encima de las barras.
title: Título del grٔáfico
sub: Título en la parte inferior
Ejemplo 5
Generemos un vector aleatorio de 60 notas entre 5 y 18 :
>x=sample(5:18,60,rep=T)
Construyamos una tabla de frecuencia simple y trazamos su histograma:
>table(x)
>hist(x)
Puesto que los datos no son adecuados para una realidad, ingresaremos otros:
> x=c(8, 10, 9, 6, 13, 13, 8, 13, 15, 9, 12, 7, 12, 7, 11, 10, 12, 7, 11, 11, 8, 8, 15, 12, 11, 11, 14, 10, 12, 9, 16, 11, 11, 10, 8, 11, 12, 14, 18, 11, 12, 10, 11, 12, 5, 9, 10, 17, 16, 12, 14, 13, 10)
Puesto que deseamos contar con una muestra de 60 datos y sólo tenemos
>length(x)
Aumentemos los que faltan
> x=c(x,12,13,12,14,12,13,15)
Probemos:
>length(x)
>table(x)
>hist(x)
Ejemplo 6
Volvamos a trabajar con histogramas
Usando los datos arriba definidos
Para el título: >xname="la tabla de frecuencia de notas"
Vector de colores: >color=c("red","blue","green","magenta")
Que ponga etiqueta, en el eje X y en el eje Y.
>hist(x,col=color,labels=TRUE,xlab="Notas",ylab="Cantidad de alumnos", main=paste ("Histogram de ",xname))
Ahora usemos la opción par:
>par(mfrow=c(1,2)) Dividimos a la ventana en dos
Volvemos a graficar:
>hist(x,col=color,labels=TRUE,xlab="Notas",ylab="Cantidad de alumnos", main=paste ("Histogram de ",xname))
Insertamos la opción freq con FALSE para disponer de las frecuencias relativas.
> hist(x,col=color,labels=TRUE,freq=FALSE,xlab="Notas",ylab="Cantidad de alumnos", main= paste("Histogram de ",xname))
La siguiente imagen muestra la gráfica
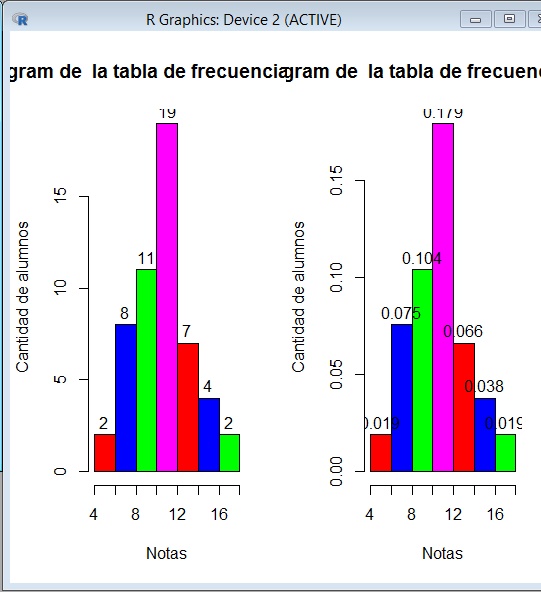
Gráfico de tallos y hojas
Es un gráfico de tipo texto.
Sintaxis
>
stem(x,scale=1,width=80)
x: Es el vector
scale: Indica la escala normal o expandida.
width: Amplitud deseada de la gráfica
>stem(x,scale=1)
Grafico circular (Pie chart)
Sintaxis
pie (x, etiquetas = nombres (x), bordes = 200, radio = 0.8, clockwise = FALSE, init.angle = if(clockwise) 90 else 0, col = NULL, borde = NULL, main = NULL ...)
donde
x: Es el vector de datos numéricos. Cada valor representa un sector del gráfico. Por ello se sugiere que x represente a la distribución de frecuencias
labels: Cadena de caracteres que representa los nombres de los segmentos circulares
clockwise: argumento lógico que indica si los sectores se trazan en sentido horario (clockwise = FALSE)
col=NULL: Define el vector de colores que pueden ser usados para cada sector.
init.angle: Valor numérico que indica el ángulo en el que se sitúa el primer sector.
main: Cadena d caracteres en la que se especifica el título del gráfico.
Ejemplo 7
Definamos el vector d:
>d=c(1,1,1,1,1,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3,3,3,3,4,4,4,4,4,5,5,5,5,5,1,1,1,2,2,2,2,2,3,3,3,3,4,4,5,5,5)
Hagamos que se convierta en factor y lo enumere
Veamos los niveles que se pueden generar con el comando factor(..)
>factor(d) Esto nos sugiere que debemos guardar los factores en una variable
>df = factor(d)
Podemos apreciar que table(d) y table(df) muestran el mismo resultado.
Definimos el nombre de los sectores por niveles de forma que nos servirán de etiqueta
>levels(df) = c("Excelente","Bueno","Regular","Malo","Pésimo") Ahora visualizamos el contenido de la variable factor df usando >df
Si usamos >table(df)
podemos apreciar que ya estamos listos para trazar un gráfico circular.
Guardemos esta tabla en una variable:
dg = table(df)
Definamos un vector de colores
> color =c("Red","Green","Blue","Orange","Yellow")
Tracemos el gráfico circular, pero con diferentes estados de los datos:
Primero los datos originales:
>pie(d) Habiendo 50 datos, genera 50 sectores, con el color predeterminado.
Luego de generar los niveles usando el comando factor(...)
>pie(df) Pide el vector de los valores de los sectores. Y, como los valores de df cambió al haber definido los niveles, hemos perdido los datos originales, aunque se conservan en d.
Por ello usamos table(df)
En efecto:
>pie(table(df))
Otra forma de hacer lo mismo es: >s=table(df) y luego >pie(s)
El gráfico obtenido usa los colores predefinidos y no el vector de colores que hemos definido. Por ello definimos:
pie(table(df), col = color)
Ahora graficamos usando título y subtítulo en main y sub, respectivamente:
>pie(table(df), col = color, main="Grafico circular de categorías",sub="Muestra las calificaciones",clockwise=TRUE)
>
El gráfico es el siguiente
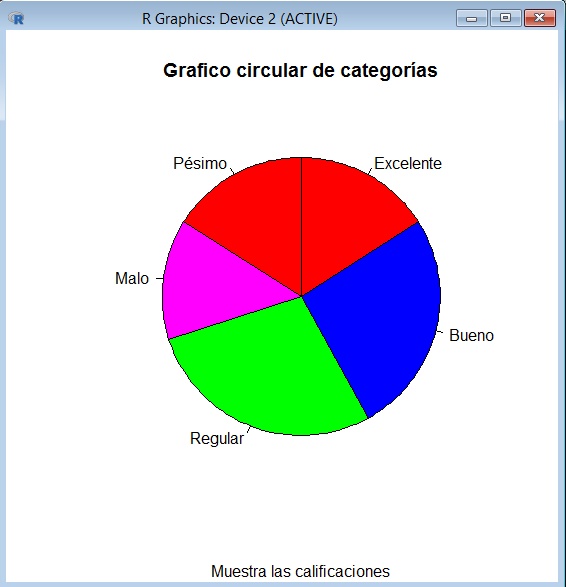
Ejemplo 8 usando varios tipos de gráfico
Vamos a abrir el archivo costocasa.xlsx que contiene los datos de un conjunto de casas. Es una hoja de Excel cuya extensión es xlsx.
Para ello, como en esta sesión no hemos instalado el paquete xlsx, procedemos a instalarlo, usando: [Paquetes] - [Instalar paquetes] - Seleccionamos [Brasil] - [Ok] Luego, seleccionamos [xlsx] - [Ok]
Ahora lo cargamos a memoria usando [Paquetes] - [Cargar paquete=""] - Seleccionamos xlsx> - [Ok]
Procedemos a leer el archivo:
> datos=read.xlsx("c:\\datosr\\costocasa.xlsx",1)
El 1, indica el número de hoja donde se encuentran los datos a ser cargados.
Podemos visualizar los datos con >datos.
Podemos pedir algunas estadísticas básicas
>summary(datos)
Los primeros datos y sus nombres
>head(datos)
Construyamos la tabla de frecuencia para el precio. Primero cargamos el módulo “fdth” usando [Paquetes] - [Cargar paquete] Seleccionamos [fdth] - [Ok]
>tfPrecio=fdt(datos$Precio)
La tabla
>tfPrecio
Ahora el histograma con barra en colores y 5 clases y como etiqueta, la frecuencia absoluta.
> hist(datos$Precio,col=c(3,5,2),nclass=5,labels=TRUE)
Una tabla de datos$Precio que indica la moda del precio
>table(datos$Precio)
Una gráfica de barras
> barplot(table(datos$Precio),col=c(3,5,2))
Un histograma de Region
>hist(table(datos$Region),col=c(5,2,7))
Una gráfica de barras (coloca los valores en orden
alfabético)
>barplot(table(datos$Region),col=c(5,2,7))
Un histograma de la variable Ofertas
> hist(datos$Ofertas,labels=TRUE,col=c(2,3,5,1))
Y un gráfico de barras
> barplot(table(datos$Ofertas),col=c(2,3,5,1))
Ahora trace un gráfico de barras de Bano y de Dorm con el vector de colores c(5,3,4,1)
Digrama de caja
A continuación, mostramos una sintaxis algo incompleta pero que es básica:
Boxplot(datos,col=NULL,xlab=NULL,ylab=NULL,main=NULL)
Ejemplo 9: Uso de los datos: mtcars
Vamos a usar una lista de datos que son propios del R y que cuando se ejecuta, los datos también se cargan.
La tabla se llama: mtcars
Listemos: >mtcars
Veamnos su estructura: >str(mtcars)
Ahora su cabecera: >head(mtcars)
Descripción de esta data que constituye una estructura.
Descripción de este objeto mtcars:
A data frame with 32 observations on 11 (numeric) variables.
[, 1] mpg Miles/(US) gallon
[, 2] cyl Number of cylinders
[, 3] disp Displacement (cu.in.)
[, 4] hp Gross horsepower
[, 5] drat Rear axle ratio (relación en el eje trasero)
[, 6] wt Weight (1000 lbs)
[, 7] qsec 1/4 mile time
[, 8] vs Engine (0 = V-shaped, 1 = straight)
[, 9] am Transmission (0 = automatic, 1 = manual)
[,10] gear Number of forward gears
Veamos algunos valores de la variable cyl y mpg (cilindrada y millas por galón)
>mtcars$cyl
>mtcars$mpg
Estadísticas de cilindrada:
>summary(mtcars$cyl)
Diagrama de cajas de la cilindrada
>boxplot(mtcars$cyl)
Otras
>boxplot(mtcars$mpg,col=c(3,5,1))
Par de gráficos un al costado del otro, en la misma ventana: Desplazamiento y peso.
> par(mfrow=c(1,2))
> boxplot(mtcars$disp,xlab="Desplazamiento",col="red")
> boxplot(mtcars$wt,xlab="Peso en libras",col="green")
A continuación se muestra estas dos gráficas en la misma ventana.
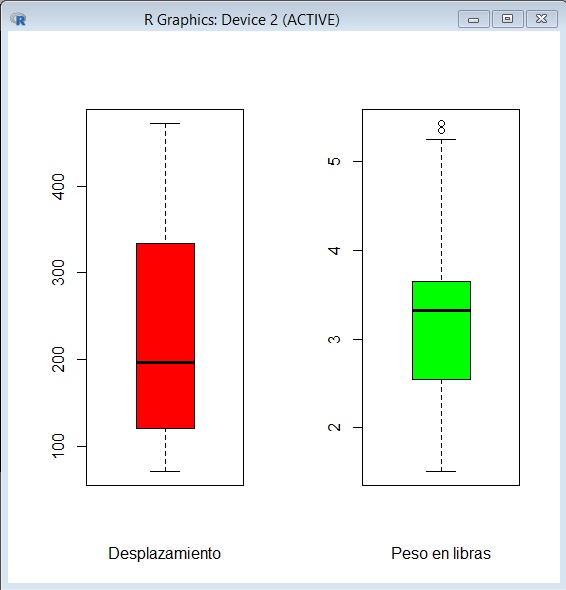
Uno debajo de otro, en la misma ventana
> par(mfrow=c(2,1))
> boxplot(mtcars$mpg,xlab="Millas por galon",col="red")
> boxplot(mtcars$wt,xlab="Peso en libras",col="green")
Colores caprichosos y tres diagramas en la misma ventana
> boxplot(mtcars$mpg*10,mtcars$hp,mtcars$disp, col=heat.colors(3,alpha=.6))
A la primera se multiplicó por 10 sólo para apreciar el gráfico.
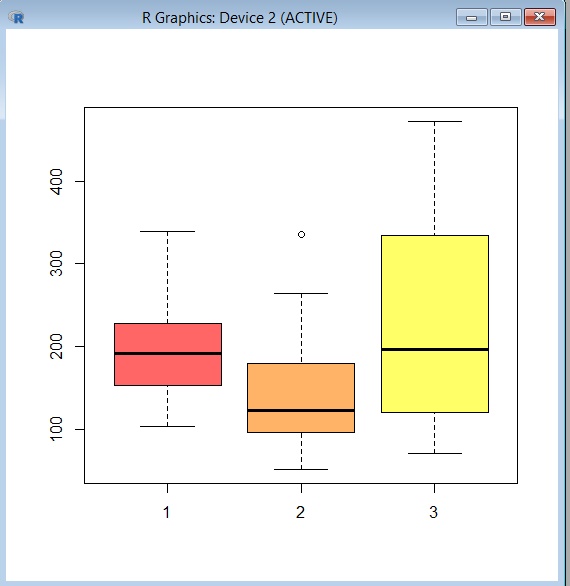
Ejemplo 10
Usaremos otros datos que vienen con el paquete:iris
Iris es un dataset (base de datos) que contiene una muestra de 50 observaciones flores de la planta iris. Hay tres tipos de clases de flores: virginica, setosa, versicolor.
Las variables que se miden son:
El tipo de flor, como variable categórica
El largo y ancho del pétalo en cm como variable numérica
El largo y ancho del sépalo en cm como variable numérica
Para acceder a los datos, versiones anteriores del R se usaba attach(iris). En esta versión es directo, ya está cargada.
Veamos los datos: >iris
Las primeras filas y ver los nombres de variable: >str(iris)
Diagrama de caja de la primera variable Sepal.Length:
>boxplot(iris$Sepal.Length)
Esta es la forma que se muestra, en forma vertical. Usemos horizontal=TRUE para rotarla
>boxplot(iris$Sepal.Length, horizontal=TRUE)
En esta orientación se puede explicar mejor el gráfico:
Ahora grafiquemos tres variables de la data; desde Sepal.Length hasta Specie.
> boxplot(iris$Sepal.Length~iris$Specie)
En forma horizontal:
> boxplot(iris$Sepal.Length~iris$Specie, horizontal=TRUE)
Usemos colores para las líneas de las cajas
> boxplot(iris$Sepal.Length~iris$Specie,horizontal=TRUE,border=c(4,2,3))
En dos gráficos de la misma ventana, uno con bordes y otro con bordes y relleno:
>par(mfrow=c(1,2))
> boxplot(iris$Sepal.Length~iris$Specie,horizontal=TRUE,border=c(4,2,3))
Ahora con relleno
> boxplot(iris$Sepal.Length~iris$Specie,horizontal=TRUE,border=c(4,2,3),col=c("red","green", "yellow"))
La siguiente imagen muestra esta gráfica.
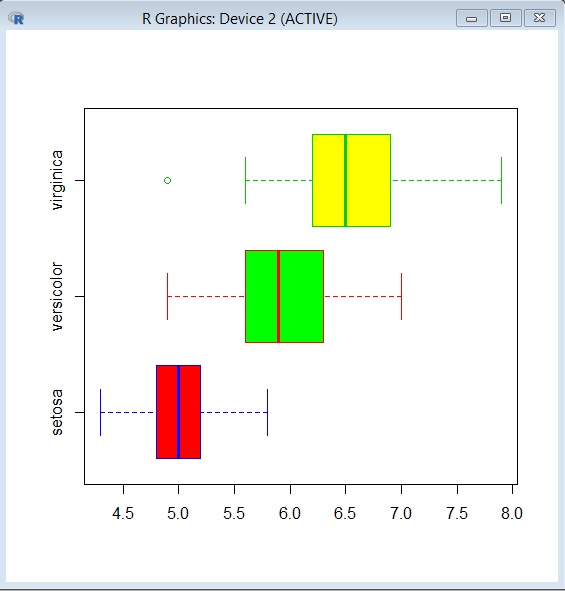
Terminamos con los gráficos bidimensionales, con el diagrama de dispersión
Diagrama de dispersión
Sintaxis
pairs(formula, data = NULL, ..., subset, na.action = stats::na.pass)
formula: Es la relación que se establece entre las variables a ser ploteadas. El conector entre variables es "~" ([alt]+123)
data: Es el data.frame cuyas variables van a ser tomadas para el diagrama
subset: Subconjunto de datos a ser ploteados.
Ejemplo
Vamos a leer otros datos de tipo texto, con separador el tabulador, sin cabecera; su nombre: agri.txt y está en D:/rpage
Definimos la cabecera
>hd = = c("ProdAg","VolFit","MaqAg","Financ")
Leemos hacia d:
> d=read.table("d:\\rpage\\agri.txt",col.names=hd,sep="\t",header=T)
>head(d)
Tracemos el diagrama de dispersión
>pairs(d, col = c("red", "green3", "blue"))
La imagen siguiente muestra el diagrama de dispersión de las variables contenidas en el data.frame d
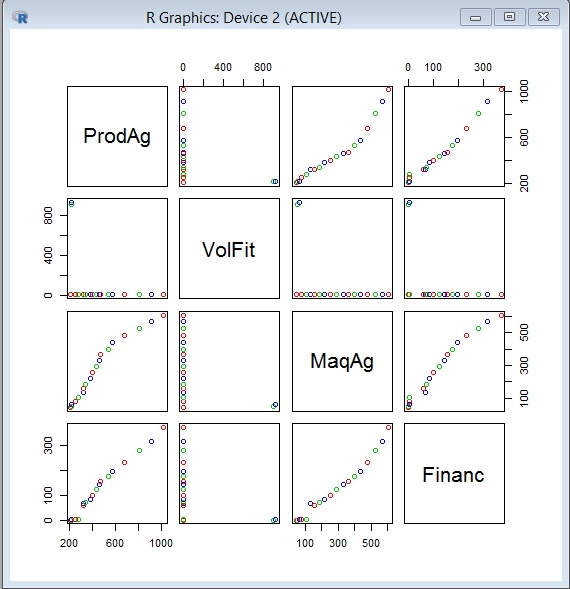
Dejamos para Ud. la interpretación de los diagramas entre estas cuatro variables.
Continuaremos en la siguiente sesión