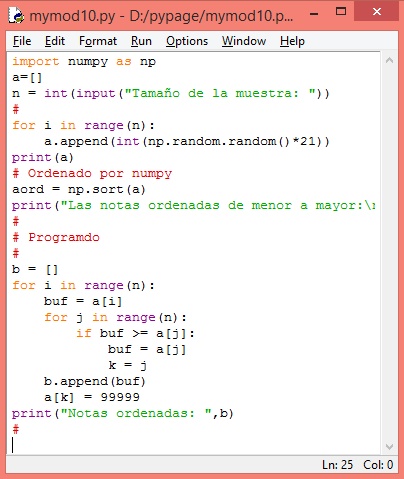
Abra un nuevo archivo para el siguiente ejemplo y grábelo con el nombre mymode10.py.
La librería numpy tiene una función llamada .sort(...) que nos permite ordenar un conjunto de objetos; sin embargo, con el ánimo de aplicar las sentencias que hemos visto, vamos a presentar las dos maneras de ordenar datos: Mediante numpy y mediante nuestro criterio.
Para ello, vamos a obtener un conjunto de notas de 0 a 20, que será nuestra muestra con la cual vamos a trabajar.
Supongamos que tenemos una muestra de tamaño n. Para generar esta muestra, haremos uso de numpy. Usaremos números aleatorios, multiplicados por 21 (np.random.random(21)) y truncaremos su parte decimal para simular notas. Esto lo haremos n veces, para lo cual uaremos la sentencia for.
El código:
import numpy as np
a=[] n = int(input("Tamaño de muestra: "))
for i in range(n):
a.append(int(np.random.random()*21))
print(a)
Vamos a ordenarlo y dejarlo en la variable aord, usando numpy
aord = np.sort(a)
print(aord)
Ahora lo vamos a codificar:
Dejaremos en b la lista ordenada
b = []
for i in range(n):
buf = a[i]
for j in range(n):
if buf >= a[j]:
buf = a[j]
k = j
b.append(buf)
a[k] = 99999
print("Notas ordenadas: ",b)
El primer for va a recorrer la lista dejando temporalmente cada a[i] en una variable de paso: buf.
Este valor es comprado con todos los elementos de la lista. Esto lo hace con el segundo for
Cada vez que el elemento en buf es mayor que el de la lista, cambia el balor de buf por el de la lista que es más pequeño y guarda el indice donde se produjo.
Cuando termine de buscar el más pequeño en la lista (termina el segundo for), añade a b este elemento que está en buf y en la posición de la lista donde encontró el más pequeño, lo llena con el más grande posible de forma que nunca más sea elegido. Al final, se imprime la lista ordenada.
La siguiente imaen contiene el código:
Sigamos con notas
En esta ocasión y vamos a contruir una tabla de frecuencia.
No hay librería que nos devuelva una tabla de frecuencia.
Solución
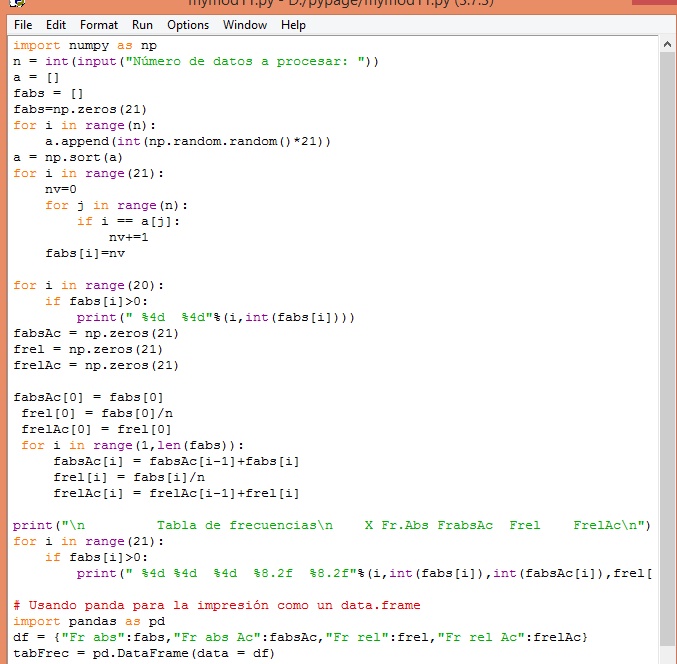
Cierre el archivo del script anterior y abra uno nuevo que lo debe grabar con el nombre mymod11.py
Las primeras líneas:
n = int(input("Número de datos a procesar: "))
a = []
Vamos a generar los datos para la simulación como el ejemplo anterior. Si se desea trabajar con otros datos, se puede usar: for i in range(n): a.append(int(input("Nota: "))).
Definimos con fabs la lista que contendrá las frecuencias absolutas, para lo cual lo inicializamos en 0:
fabs = []
fabs=np.zeros(21)
Vamos a leer los datos aleatorios de tamaño n:
for i in range(n):
a.append(int(np.random.random()*21))
Lo ordenamos de menor a mayor.
a = np.sort(a)
Ahora, para cada nota de 0 a 20 (for i in range(21), vamos a ver cuantas de ellas está en la lista. Si estuviera, aumentamos en uno la variable que guarda el conteo: nv.
Cuando termine de recorrer todas las notas, guarda el conteo en fabs y vuelve al primer for para pasar a la siguiente nota
for i in range(21):
nv=0
for j in range(n):
if i == a[j]:
nv+=1
fabs[i]=nv
A continuación, pasamos a imprimir las notas y su frecuencia o número de veces que se repite en la lista.
for i in range(20):
if fabs[i]>0:
print(" %4d %4d"%(i,int(fabs[i])))
Prcedemos a calcular la frecuencia absoluta acumulada fabsAc, la frecuncia relativa frel y la frecuencia relativa acumulada frelAc.
Primero inicializamos en 0 estos arreglos
fabsAc = np.zeros(21)
frel = np.zeros(21)
frelAc = np.zeros(21)
Ahora empezamos con la obtención de las tres frecuencias
fabsAc[0] = fabs[0]
frel[0] = fabs[0]/n
frelAc[0] = frel[0]
for i in range(1,len(fabs)):
fabsAc[i] = fabsAc[i-1]+fabs[i]
frel[i] = fabs[i]/n
frelAc[i] = frelAc[i-1]+frel[i]
Pasamos a imprimir de acuerdo a nuestro criterio
print("\n Tabla de frecuencias\n X Fr.Abs FrabsAc Frel FrelAc\n")
for i in range(21):
if fabs[i]>0:
print(" %4d %4d %4d %8.2f %8.2f"%(i,int(fabs[i]),int(fabsAc[i]),frel[i],frelAc[i]))
Usaremos pandas sólo para tomar a nuestra tabla y con la estructura de un data.frame, lo imprima de una forma muy elemental y rápida.
print("\n\nUsando la librería de pandas")
import pandas as pd
df = {"Fr abs":fabs,"Fr abs Ac":fabsAc,"Fr rel":frel,"Fr rel Ac":frelAc}
tabFrec = pd.DataFrame(data = df)
print(tabFrec)
La siguiente imagen muestra este código o script
El ejemplo anterior, nos permite obtener una tabla de frecuencias para datos no agrupados; es decir, cuando los datos son pocos y por lo general son ordinales o categóricos.
En este ejemplo vamos a simular una muestra de tamaño n (n>30).
Supongamos que se trata de una muestra de los ingresos mensuales de n trabajadores.
Abra un nuevo archivo de script para grabar el código de este ejemplo. Guárdelo con el nombre de mymod12.py
Recuerde que vamos a usar numpy por tanto importamos esta librería
Primero leemos el tamaño de la muestra en n. Luego simulamos tener n ingresos mensuales entre 1200 y 5000 soles en datos
A continuación pasamos a determinar el máximo (xmax), el mínimo en xmin, el número de intervalos por la regla de sturges en k, el ancho o amplitud del intervalo en c.
Luego procedemos a determinar el límite mínimo (LimInf) y máximo (LimSup) de cada intervalo.
Inicializamos las listas: fabs, fAc, frel, frAc en 0, a fin de determinar sus elementos.
El doble for que viene permite contar el número de datos que se encuentra entre el límite inferior y superior de cada intervalo.
Después procedemos a obtener las frecuencias restantes.
Finalmente procedemos a la impresión de la tabla.
Las siguientes líneas corresponde al código que resuelve el problema. Copie o digite en su archivo mymod11.py. Luego grabe y ejecútelo.
import numpy as np
# Lectura del tamaño de muestra
n = int(input("Tamaño de muestra: "))
datos = []
# Generación de los n datos
for i in range(n):
datos.append(np.random.randint(1200,5000))
# Determinación del min y max de los datos con numpy
xmin = np.min(datos)
xmax = np.max(datos)
# Obtención del número de intervalos o clases según la regla de Sturges
k = 1+int(np.log(n)/np.log(2))
# Determinación de la longitud del intervalo
c = (xmax-xmin)/k
# Inicializamos los vectores que serán los extremos de cada intercalo
LimInf = np.zeros(k)
LimSup = np.zeros(k)
# Determinamos el límite inferior y seperior del primer intervalo
LimInf[0] = xmin
LimSup[0] = c+LimInf[0]
# Deerminamos el límite inferior y superior de los siguientes intervalos<br>
for i in range(1,k):
LimInf[i] = LimSup[i-1]
LimSup[i] = c + LimInf[i]
# Ahora pasamos a obtener la frecuencia absoluta
fabs =np.zeros(k)
fAc = np.zeros(k)
frel = np.zeros(k)
frAc = np.zeros(k)
for i in range(k):
for j in range(n):
if datos[j] <= LimSup[i] and datos[j] >= LimInf[i]:
fabs[i]+=1
# Obtención de las otras frecuencia
fAc[0] = fabs[0]
frel[0] = fabs[0]/n
frAc[0] = frel[0]
for i in range(1,k):
fAc[i] = fAc[i-1] + fabs[i]
frel[i] = fabs[i]/n
frAc[i] = frAc[i-1]+frel[i]
print("\n Tabla de frecuencias\n X Fr.Abs FrabsAc Frel FrelAc\n")
for i in range(k):
if fabs[i]>0:
print(" %4d %4d %4d %8.2f %8.2f"%(i,int(fabs[i]),int(fAc[i]),frel[i],frAc[i]))
La siguiente imagen muestra parte de este script.