Ejemplo 3
Trabajemos con matrices. Dada una matriz de orden (n,m), vamos a leer n y m; luego leeremos la matriz A(n,m) para después imprimirla. Le lectura la haremos for fila (1, 2, ..., n); eso requiere de un for i in range(n). Y, por cada fila, vamos a leer todas las columnas (1, 2, ...., m); eso requiere de un for j in range(m). Esta será también la forma de imprimirla.
Solución
Empecemos por
import numpy as np
Definamos dos listas. La primera, a, para recibir con append, lo que se lee. La segunda, b, para recibir toda la fila capturada en a. No olvidar que, cada vez que vuelva a incrementar en fila, la lista a debe estar vacía.
a = []
b = []
Leemos el valor de n:
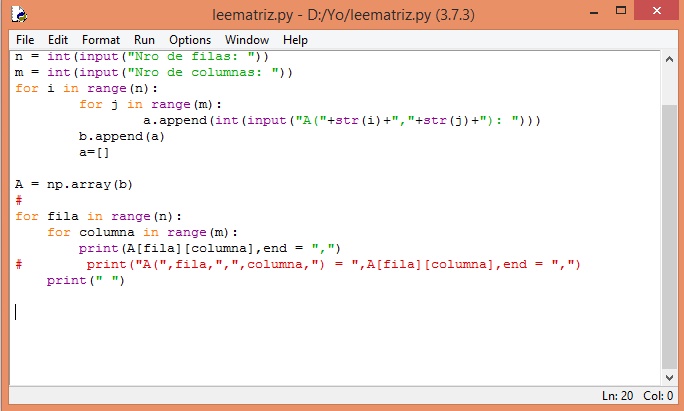
n = int(input("Nro de filas: ")
Ahora leemos el valor de m:
m = int(input("Nro de columnas: ")
Ahora usamos un for para las filas: for fila in range(n). Y por cada valor que tome su variable filas, usamos un for para leer todas las columnas: for columna in range(m)
Dentro de este for, añadimos elementos ingresados usando input(...)
for i in range(n):
for j in range(m):
a.append(int(input("A("+str(i)+","+str(j)+"): ")))
b.append(a)
a=[]
El for interno se encarga de leer todas las columnas de la i-ésima fila. Cuando termina, la siguiente línea es b.append(a) pues toda la lista a, se añade a b que va ser lista de listas. Luego de esto, se hace a = [] pues debe crearse la siguiente lista con el siguiente valor de i.
Ahora vamos a convertir en un arreglo bidimensional en A según la siguiente línea, porque b es lista de listas.
A = np.array(b)
Finalmente codificamos el procedimiento de impresión:
for fila in range(n):
for columna in range(m):
print(A[fila][columna],end = ",")
# print("A(",fila,",",columna,") = ",A[fila][columna],end = ",")
print(" ")
El print que está con "#" es un comentario. Hemos usado el primero que es más comprensible.
Como se puede ver, se imprime elemento por elemento. El segundo argumento del print: "end = ",", haceque los elementos de 0 a m (toda la iésima fila) se imprima una al costado de la otra. De otra manera lo imprimiría hacia debajo.
El print(" ") se ejecuta cuando haya terminado el for interno. Este print, no teniendo el argumento end = ",", cambia de línea.
El módulo debe contener todas las líneas en negrita.
Grabe con el nombre leematriz.py.
La siguiente imagen muestra el código
Ejemplo 4
Abra un nuevo archivo usando: [File] - [File new]. Luego grabe usando [File] - [Save as ...], con el nombre mymod09.py
Ahora va a digitar todo lo que aquí encuentre en negrita
import numpy as np
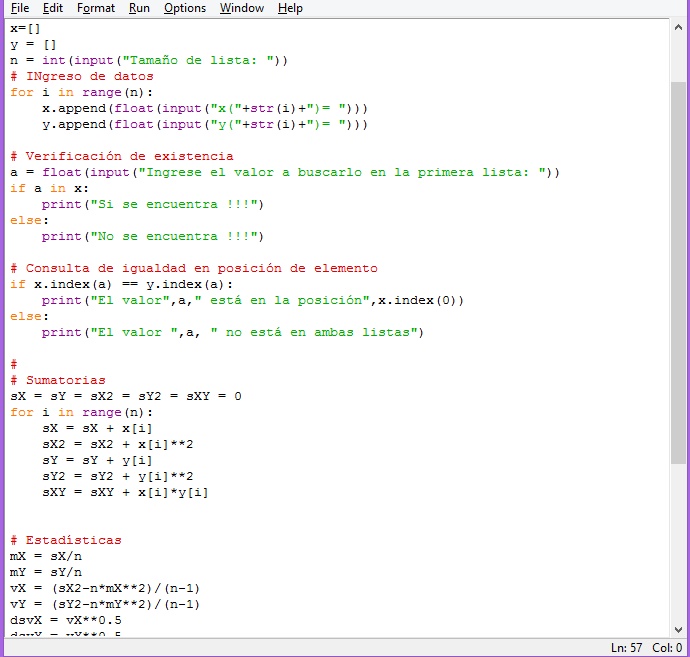
Vamos a calcular los estdísticos descriptivos sin utilizar numpy. Sólo con el ánimo de aprender a programar. Usaremos las funciones de numpy para comprobar lo que hemos calculado.
Primero vamos a leer dos listas de tamaño n.
Verificar si cierto elemento está en la primera lista
Verificar si un determinado elemento está en la misma posición, en ambas listas
Obtener la suma, la diferencia, el producto vectorial, producto escalar, la media, varianza, desviación estándar y coeficiente de variación de cada lista; la covarianza y coeficiente de correlación de ambas listas.
Solución
Definimos las dos listas
x=[]
y = []
Lectura del tamaño de la lista:
n = int(input("Tamaño de lista: "))
Lectura simultánea de ambas listas con valores reales (con decimales), para lo cual usamos float
for i in range(n):
x.append(float(input("x("+str(i)+")= ")))
y.append(float(input("y("+str(i)+")= ")))
Verificaremos si un valor, digamos a (que debe ser leído), está en la lista:
a = float(input("Ingrese el valor a buscarlo en la primera lista: "))
Veamos:
if a in x:
print("Si se encuentra !!!")
else:
print("No se encuentra !!!")
Ahora vamos a ver si este valor "a" se encuentra en la misma posición, en ambas listas
if x.index(a) == y.index(a):
print("El valor",a," está en la posición",x.index(0))
else:
print("El valor ",a, " no está en ambas listas")
Nota
Para que la consulta sea positiva, sugerimos que ingrese los siguientes datos:
Para el tamaño de la lista: 10
Para la primera lista, x: 2, 7, 2, 5, 7, 5, 0, 8, 2, 3
Para la segunda lista, y: 3, 6, 8, 2, -5, 9, 0, 3, -8, 4
Para el elemento a buscar en la primera lista: 0
Luego de la primera prueba, Ud. ingrese los valores que desee.
Ahora pasmos a los cálculos descriptivos, paralelamente en ambas listas
Inicializamos variables que acumularán las sumas: sX, sY, sX2, sY2, sXY (la variable sugiere el tipo de suma que almacenará).
sX = sY = sX2 = sY2 = sXY = 0
for i in range(n):
sX = sX + x[i]
sX2 = sX2 + x[i]**2
sY = sY + y[i]
sY2 = sY2 + y[i]**2
sXY = sXY + x[i]*y[i]
Pasamos a calcular las medias: mX, mY; las varianzas: vX, vY; las desv. estándar: dsvX, dsvY; los coeficientes de variación: cvX, cvY; la covarianza de X e y: covXY; el coeficiente de correlación de X e Y: corXY
mX = sX/n
mY = sY/n
vX = (sX2-n*mX**2)/(n-1
vY = (sY2-n*mY**2)/(n-1)
dsvX = vX**0.5
dsvY = vY**0.5
cvX = dsvX/mX
cvY = dsvY/mY
covXY = (sXY-n*mX*mY)/n
corXY = covXY/(vX*vY)**0.5
Impresión de resultados
for i in range(n):
print(" %4.1f %4.1f"%(x[i],y[i]))
Ahora las estadísticas
print("\n\nEstadísticas: X Y\nMedias: %28.2f %7.2f\nVarianzas: %26.3f %7.3f\nDesviación estándar: %15.2f %8.2f\nCoeficiente de variación: %11.3f %7.3f\nCovarianza: %25.3f\nCoeficiente de correlación: %8.2f"%(mX, mY, vX, vY, dsvX, dsvY, cvX, cvY,covXY,corXY))
Digite todas las líneas en negrita en el archivo que hemos abierto. Cuando termine, grábelo con el nombre mumod09.py.
Finalmente, pase a ejecutar el módulo usando [Run] - [Run module]
La siguiente imagen muestra parte del procedimiento que debe ser grabado.